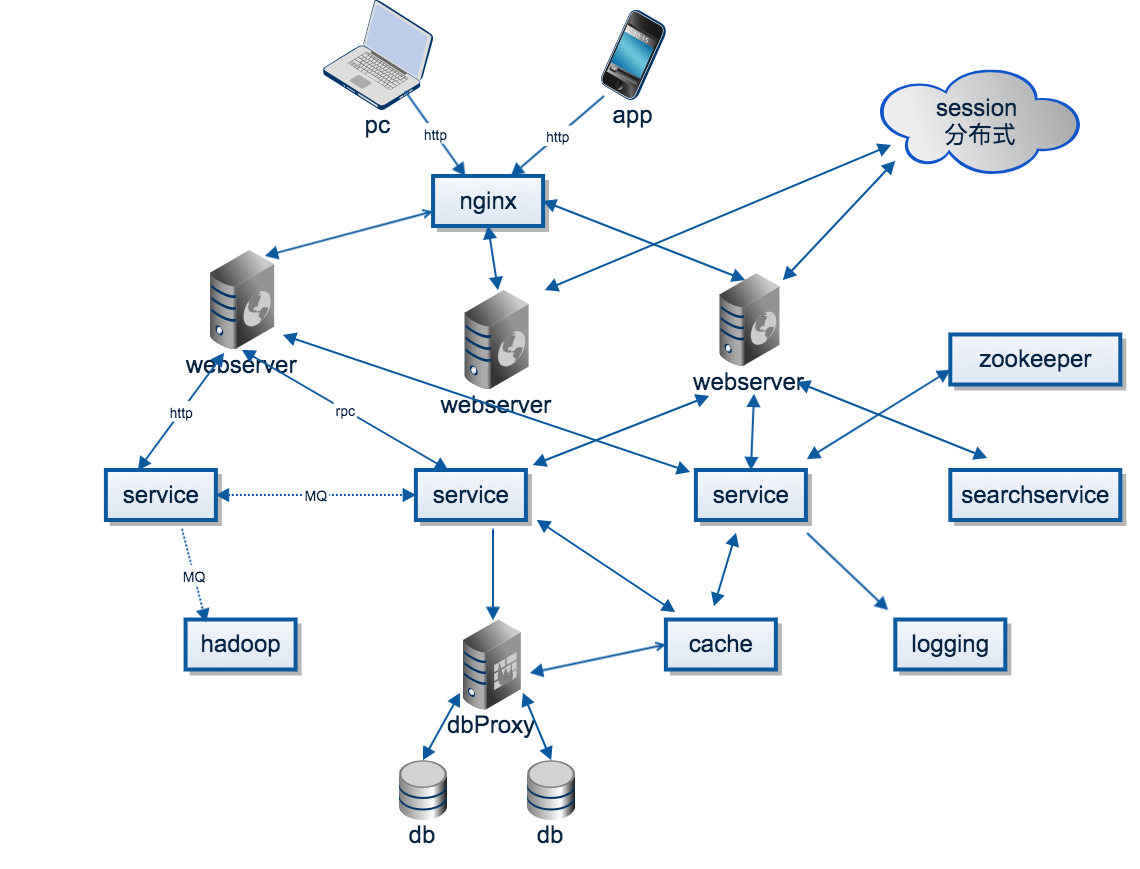
什么是分布式系统,如何学习分布式系统
抛出问题:
一个对外提供服务的大型分布式系统,用户访问这个系统,做一些操作,产生需要存储的数据,在这个过程中,有哪些组件、协议和调用?
请求
Web浏览器、APP客户端、SDK组件
负载均衡
在分布式系统中,为了高并发、高可用,一般是多个节点服务器提供相同的服务,由load balance选择哪个节点来提供服务
系统调用
节点服务器开始处理用户的请求,简单请求,可能是有缓存的,即分布式缓存。如果缓存没有,那么去数据库拉取数据。
复杂请求,即系统A需要调用系统B的服务,但是,每个应用都手写socket是一件冗杂、低效的事情,因此需要应用层的封装,因此有了HTTP接口。如果系统愈加复杂,大量的HTTP接口也是一件困难的事情,因此进一步的抽象,就是RPC(remote produce call),远程调用就跟本地过程调用一样方便,屏蔽了网络通信等诸多细节(一般公司使用dubbo框架实现RPC远程调用)。
总结:socket—–HTTP接口—–RPC
注册中心
一个请求包含多个操作,其实就是涉及到多个服务,分布式系统中有大量的服务,每个服务又是多个节点组成。那么一个服务怎么找到另一个服务(的某个节点呢)?
通信是需要地址的,怎么获取这个地址,最简单的办法就是配置文件写死,或者写入到数据库,但这些方法在节点数据巨大、节点动态增删的时候都不大方便,这个时候就需要服务注册与发现:提供服务的节点向一个协调中心注册自己的地址,使用服务的节点去协调中心拉取地址。
从上可以看见,协调中心提供了中心化的服务:以一组节点提供类似单点的服务,使用非常广泛,比如命令服务、分布式锁。协调中心最出名的就是zookeeper,chubby。
消息队列
回到用户请求这个点,请求操作会产生一些数据、日志,其他一些系统可能会对这些消息感兴趣,比如个性化推荐、监控等,这里就抽象出了两个概念,消息的生产者与消费者。那么生产者怎么将消息发送给消费者呢,RPC并不是一个很好的选择,因为RPC肯定得指定消息发给谁,但实际的情况是生产者并不清楚、也不关心谁会消费这个消息,这个时候消息队列就出马了。简单来说,生产者只用往消息队列里面发就行了,队列会将消息按主题(topic)分发给关注这个主题的消费者。消息队列起到了异步处理、应用解耦的作用。
分布式计算
上面提到,用户操作会产生一些数据,这些数据忠实记录了用户的操作习惯、喜好,是各行各业最宝贵的财富。比如各种推荐、广告投放、自动识别。这就催生了分布式计算平台,比如Hadoop,Storm等,用来处理这些海量的数据。
分布式存储
最后,用户的操作完成之后,用户的数据需要持久化,但数据量很大,大到按个节点无法存储,那么这个时候就需要分布式存储:将数据进行划分放在不同的节点上,同时,为了防止数据的丢失,每一份数据会保存多分。传统的关系型数据库是单点存储,为了在应用层透明的情况下分库分表,会引用额外的代理层。而对于NoSql,一般天然支持分布式。
| 组件 | 技术栈 | 说明 |
|---|---|---|
| 负载均衡 | Nginx | 负载均衡、反向代理、静态内容缓存,工作在应用层 |
| 负载均衡 | LVS | 高性能、高可用的服务器,工作在网络层 |
| WEB server | Java:Tomcat、Apache、Jboss、Weblogic | Weblogic收费 |
| service | SOA | |
| service | 微服务 | 主要是后端服务拆分 |
| service | spring boot | 后端 |
| service | django | 后端 |
| - | VUE | 前端 |
| 容器 | docker | |
| 容器 | k8s | |
| cache | memchache | |
| cache | redis | |
| 协调中心 | zookeeper | java开发的,被Apache很多项目采用 |
| 协调中心 | etcd | 在分布式环境下的key/value存储服务,用于共享配置信息或服务发现,主要是被K8s采用 |
| RPC框架 | dubbo | |
| 消息队列 | kafka | |
| 消息队列 | rabbitMQ | |
| 消息队列 | rocketMQ | |
| 实时数据 | storm | |
| 离线数据平台 | Hadoop | |
| 离线数据平台 | spark | |
| dbproxy | cobar | |
| DB | MySQL、Oracle、MongoDB、HBase | |
| 搜索 | elasticsearch | |
| 日志 | rsyslog | |
| 日志 | elk | |
| 日志 | flume |
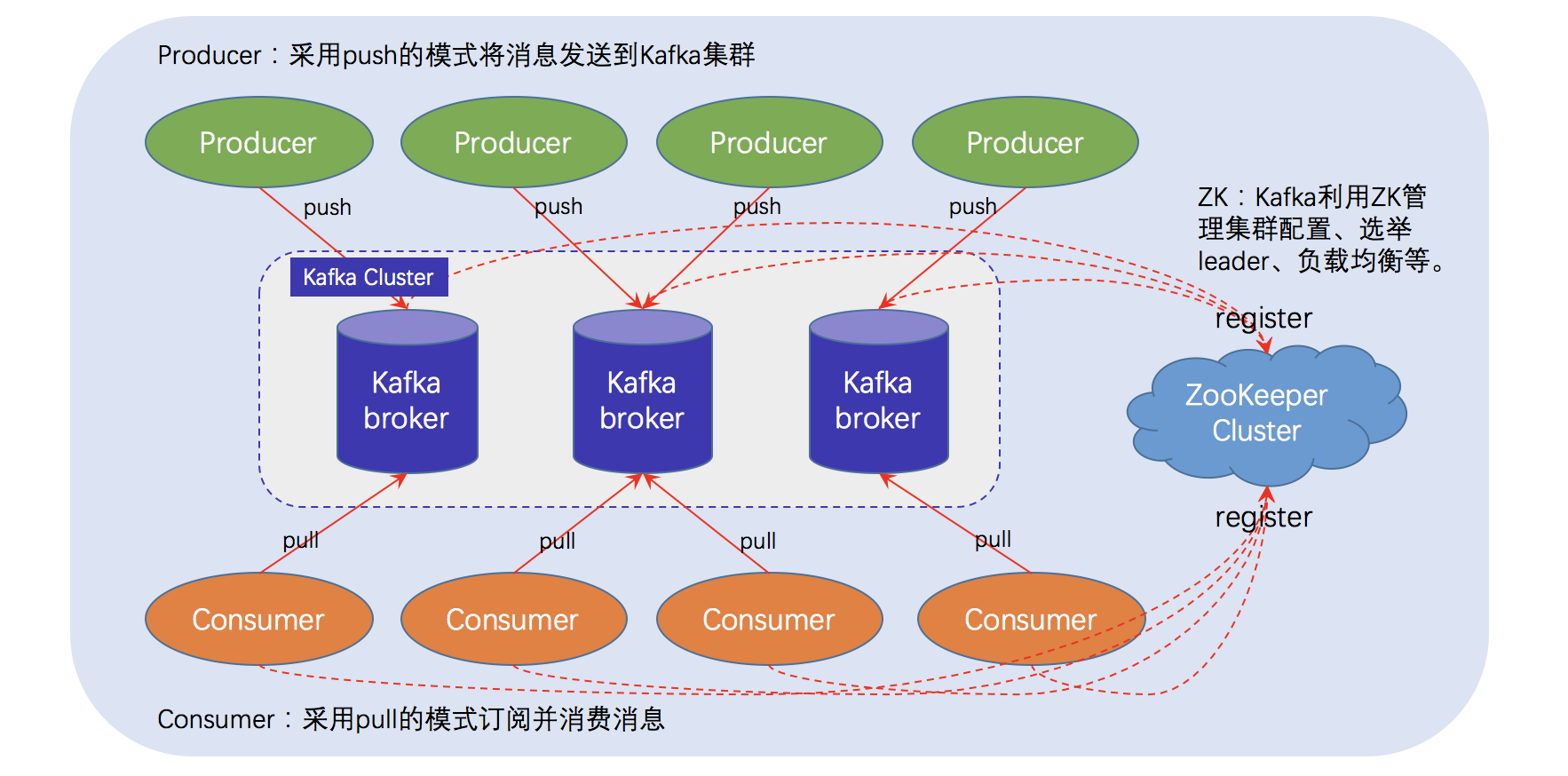
Kafka-ZooKeeper分布式消息队列系统架构: